
If you are a manufacturing operations leader, the ability to make data-driven decisions in near real-time is most likely a very important goal of yours. If you are a business intelligence analyst focused on gleaning ways to improve the business across the entire supply chain, robust data sources are of great value, especially from the manufacturing operations, which is the most important link in the supply chain. If you are a maintenance leader, being able to get to asset data to drive your condition-based and predictive initiatives is very important to the future success of your team — and so it goes, on and on. All these scenarios rely on the access to, and the readability of, manufacturing operational data in a way that does not interrupt operations or put critical control systems at risk. This article will focus on how to make that a reality.
Critical Data Elements
For discussion purposes, let’s use the term data enablement, which in this context is defined as the process that translates all the bits, bytes and strings of data that the manufacturing operations generate into accessible, readable information. The general data stakeholder community (i.e., the operations team, quality team, product engineering / R&D, maintenance, business intelligence analyst, etc.) can then leverage this information without reliance on the process engineering group or IT team to retrieve and translate it.
Data enablement done right requires some fundamental elements, such as collection, structure / governance / contextualization, analytics and socialization. Let’s delve into each of these elements beginning with collection.
Collection
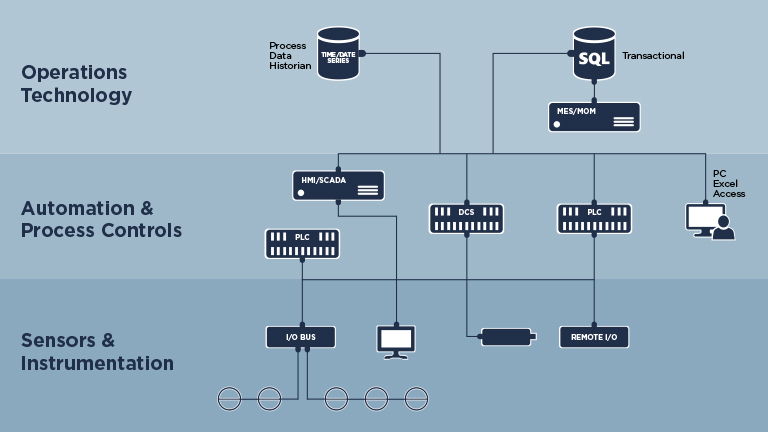
This element may sound basic, but it is a critical foundational element. It needs to be done correctly, starting with the process data, which is the time series data that the sensors and instrumentation generate, along with the calculated values generated within the process systems. This data is captured within the automation controls layer, which is mission critical data. You should not have anyone, except the automation control experts, accessing it. Therefore, this data needs to be extracted into a repository that puts it into a different layer and keeps the automation controls layer isolated and secure. The preferred way of doing this is via a process data historian. Examples of the common historian platforms in the industry would be OSIsoft PI, AspenTech IP21 and Rockwell Automation’s FactoryTalk Historian.
Process data is only half of the collection element; the other half is the transactional data. This is the all-important operation event header type records (i.e., batch numbers, lot numbers, order numbers, quality samples, downtime events, work orders, etc.) To be useful and manageable, this data needs to be kept in a relational database format, like a SQL-based database. Common system platforms for the collection, generation, organization and management of this data are manufacturing execution system (MES), manufacturing operations management (MOM), quality management system / laboratory information system (QMS / LIMS), enterprise asset management / computerized maintenance management system (EAM / CMMS) and of course, enterprise resource planning (ERP).
Structured and Contextualized Data
Process data collection by itself does little good other than ensure there is a historical record. Left as is, this valuable operational insight data is highly cryptic to the general data stakeholder community. To make this data useful, the data needs to be structured and contextualized to enable an easy and intuitive way to find, access and read the data. The best way to structure the data is via a data model. A data model facilitates common terminology and structure for data governance, ease of access and optimal integration between systems. Examples of common data models are the ISA-S95 model for hierarchical structures, and the ISA-S88 model for batch-based processes.
Here are a couple macro visuals of these structures:

Once a data model has been selected, now it’s time for the Midas touch — organizing the data within this model and adding the correct contextualization. For the general data stakeholder community, this is the key between your process data being usable or not. The structure organizes the data in a way that makes it intuitively easy to find. The contextualization allows the relabeling of this native cryptic data into vernacular that is familiar to the general data stakeholder. This relabeling is done without ever changing the original tag and data point names down in the automation controls layer. Relabeling maps the new name to the original tag or data point name that is returning the actual value. This is at the heart of data enablement in the context of this article.
Most of the contemporary data historians and operations technology systems, like MES and enterprise manufacturing intelligence (EMI) solutions, incorporate tools that facilitate these data structures. Examples are OSIsoft’s Asset Frameworks, AspenTech’s mMDM and Rockwell Automation’s FactoryTalk Historian AF. The key here is to make sure a “common” data model approach is used across all systems to ensure proper governance and help maximize interoperability between systems.
The following two illustrations demonstrate life for the data stakeholder community before and after data modeling with contextualization:

Having data that the general data stakeholder community can intuitively find and easily read reduces the operational friction that exists without it. For example, your process engineering staff will not have to burn valuable time doing data mining for people interested in data analysis that requires process data. The operations team can now quickly locate data for key performance indicator (KPI) generation, performance reports and root-cause analysis to operational issues.
This leads to our next element of data enablement — analyzing the data now that you have it accessible and readable.
Analytics
Basic analysis of process data is accomplished with native Microsoft Excel connectivity tools or the historical trending tools found in many human-machine interface / supervisory control and data acquisition (HMI / SCADA) platforms. Typical examples of analysis are:
- Trending of rates, flows and temperatures over time
- Threshold determination
- Auto population of Excel-based reports
I have seen some amazing reports and analysis accomplished using these Excel add-in tools. As the old adage goes, with enough time and money, you can accomplish anything. However, who has that kind of time? The time it takes to formulate, manage and execute long-term support with this approach for anything other than the basics quickly becomes unsustainable.
A better approach is to use the fit-for-purpose analysis tools offered by historian OEMs (e.g., OSIsoft’s Vision or AspenTech’s ProcessExplorer). These platforms offer ad-hoc style analysis tools complete with navigational tools that allow the data stakeholders to leverage the data model and contextualization efforts. Use case examples for these tools would be:
- Asset performance profiles
- Current batch vs. golden batch performance
- Threshold detection and determination for condition-based maintenance
- Pre-event vs. post-event pattern analysis
- KPI performance dashboarding
The one caveat is these tools are very fit-for-purpose (i.e., they work best when they are using data sources within their own product portfolio set). There are ways to connect to external sources but not in the most native of fashion, and there is usually a stiff commercial price to do so.
The above yields some very valuable intelligence. However, the value equation goes up even further when we marry the process data to the transactional data mentioned earlier. Now you can make things interesting and insightful for the wider data community. Using universal EMI tools like Rockwell Automation’s VantagePoint or PTCs ThingWorx, are a couple examples. These tools, and others, are designed to connect to data sources in the manufacturing operations technology space, mainly, OPC, most historians and SQL, and they leverage and/or facilitate the common data models.
These tools enable the data stakeholders to cast a wider data analysis net across the multiple data silos. For example, they can now analyze process data in the data historian against the transactional data in one or many relational databases natively. Some use cases for that would be:
- Yield, efficiency and energy consumption by:
- Product
- Lot, order or batch
- Shift, day or time of year
- Asset
- Impact to yield, efficiency and energy consumption when a change in a quality spec, material or a process has been made
- Material performance by vendor, product type or asset
- KPI performance automation and dashboarding
To go a step further, data enablement can be a great accelerator for the predictive analysis tools that are now mainstream thanks to artificial intelligence (AI) and pattern recognition. These technologies work best when there is historical time / date alignment between the process data and the event data, like maintenance work orders or downtime events. Data enablement, done correctly, will expose this data to the stakeholders.
Socialization
Now that you have the data stakeholder community empowered with structured, accessible, readable data and the analytical tools to use it, it is time to socialize the results, which leads to our last element of data enablement, socialization. It is important to note that there are varying degrees of interest across a given enterprise. MESA International refers to this as the divergent perspective (see the graphic).

Source: MESA International
Basically, the interest of leadership from a corporate perspective is going to be vastly different than the interest at a line or department level at a site. The interest at a plant management level is going to be a mixture of both high and low, which is natural. A good socialization solution needs to address all these interests and needs to have access to the data to support these divergent interests. There are many different approaches from a technology perspective; for example, Rockwell’s VantagePoint, but there are other options, such as ThingWorx from PTC, which looks interesting. Microsoft’s PowerBI is also getting a lot of traction due to its adoption by the back-office crowd. When selecting a specific technology layer, consider the data sources the system needs to source, the existing enterprise analysis and visualization tools already in place, the entire user community needs and the client hardware platforms that will require support.
So, where do you start the data enablement journey? What are the incremental steps that align best with your existing infrastructure and organizational needs? How do you select the correct technology to fill the gaps that exist? How do you build a business justification? To answer these questions, you must first understand that data enablement is all about making data accessible and useable to your wider enterprise to enable a deeper and more timely understanding of your operation. Whether you start this journey on your own or consult with an automation solutions provider, think about what data enablement can do for your business if executed correctly. Data enablement ensures the right data, in the right form, is available to the right person at the right time.